

根据观测、调查收集到初步的样本数据集后,接下来需要考虑的问题是:样本数据集的数量和质量是否满足模型构建的要求?有没有出现从未设想过的数据状态?其中有没有明显的规律和趋势?各因素之间有什么样的关联性?
通过检验数据集的数据质量、绘制图表、计算某些特征量等手段,对样本的结构和规律进行分析的过程就是数据探索。数据探索有助于选择合适的数据预处理和建模方法,甚至完成一些通常由数据挖掘解决的问题。
数据质量分析是数据挖掘中数据准备过程中的重要一环,是数据处理的前提。数据质量分析主要任务是检查原始数据中是否存在脏数据。
脏数据一般是指不符合要求以及不能直接进行相应分析的数据。在常见的数据挖掘中,脏数据包括:缺失值、异常值、重复数据及含有特殊符号(如#、¥、*)的数据。
数据的缺失主要包括记录的缺失和记录中某个字段信息的缺失,两者都会造成分析结果的不准确。
缺失值产生的原因
缺失值产生的原因主要有以下$3$点:
缺失值的影响
缺失值的分析
对缺失值的分析主要从以下两个方面进行:
异常值分析是检验数据是否有 输入错误,是否含有 不合常理的数据。忽视异常值的存在是很危险的,不加剔除的将异常值放入数据的计算分析过程中,会对结果造成不良影响;重视异常值的出现,分析其产生的原因,常常成为发现问题进而改进决策的契机 。
异常值是指样本中的个体值,其数值明显 偏离 其他的观测值。异常值也称为 离群点 ,异常值分析也称为离群点分析。
简单统计量分析
在进行异常值分析时,可以先对变量做一个描述性统计,进而查看哪些数据是不合理的。最常用的统计量为最大值和最小值 ,用来判断这个变量的取值是否超出了合理范围。
$3 \sigma$原则
如果数据服从正态分布,在$3\sigma$原则下,异常值被定义为 一组测定值中与平均值的偏差超过3倍标准查的值。在正态分布的假设下,距离平均值$3\sigma$之外的值出现的概率为$P(x-\mu|>3\sigma)\leq 0.003$ ,属于极个别的小概率事件。
如果数据不服从正态分布,也可以用远离平均值的标准差倍数来描述。
箱型图分析
箱型图提供了识别异常值的一个标准:异常值通常被定义为小于$Q_L-1.5IQR$或大于$Q_U+1.5IQR$的值。$Q_L$称为下四分位数,表示全部观察值中有四分之一的数据取值比它小;$Q_U$称为上四分位数,表示全部观察值中有四分之一的数据取值比它大;$IQR$称为四分位数间距,是上四分位数$Q_U$如与下四分位数$Q_L$之差,其间包含了全部观察值的一半。
**箱型图依据实际数据绘制,对数据没有任何限制性要求,**如服从某种特定的分布形式,它只是真实直观地表现数据分布的本来面貌;另一方面,箱型图判断异常值的标准以四分位数和四分位距为基础,四分位数具有一定的鲁棒性:多达25%的数据可以变得任意远而不会严重扰动四分位数,所以异常值不能对这个标准施加影响。由此可见,箱型图识别异常值的结果比较客观在识别异常值方面有一定的优越性。
餐饮系统中的销量数据可能出现缺失值和异常值例如下表所示。
| 时间 | 2015/2/10 | 2015/2/11 | 2015/2/12 | 2015/2/13 | 2015/2/14 |
|---|---|---|---|---|---|
| 日销额(元) | 2742.8 | 3014.3 | 865.0 | 3036.8 |
分析餐饮系统日销额数据可以发现,其中有部分数据是缺失的,但是如果数据记录和属性较多,使用人工分辨的方法就不是很现实,通过编写程序来检测出含有缺失值的记录和属性以及缺失值个数和缺失率等。
# -*- coding: utf-8 -*-
# 使用describe()方法查看数据的基本情况
import pandas as pd
catering_sale = '../data/catering_sale.xls' # 餐饮数据
data = pd.read_excel(catering_sale,index_col = "日期") # 读取数据,指定"日期"作为索引列
print(data.describe())
输出:
销量
count 200.000000
mean 2755.214700
std 751.029772
min 22.000000
25% 2451.975000
50% 2655.850000
75% 3026.125000
max 9106.440000
其中count是非空值数,通过len(data)可以知道数据记录为201条,因此缺失值为1。另外,提供的基本参数还有平均值mean、标准差std、最小值min、最大值max以及1/4、1/2、3/4分位数($25%、50%、75%$)。
更直观地展示这些数据并且可以检测异常值的方法是使用箱型图。
# -*- coding: utf-8 -*-
# 使用箱型图检测异常值
import matplotlib.pyplot as plt # 导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure() # 建立图像
'''
使用DataFrame中的boxplot方法,绘制箱型图,并将返回值赋给变量p。
返回的是一个字典类型,包含了箱体、上下边缘、中位数等信息。
'''
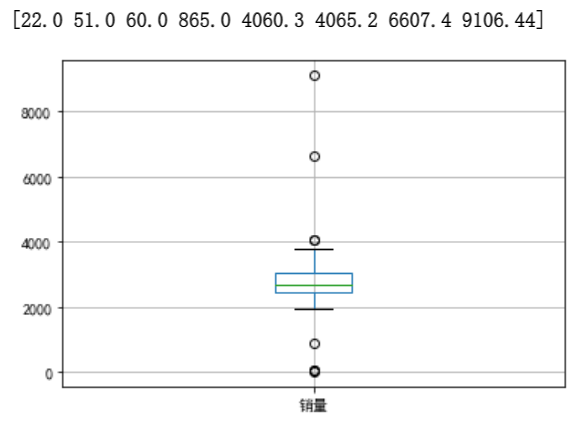
p = data.boxplot(return_type = 'dict') # 画箱型图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata() # 从绘制的箱型图p中获取异常值的横纵坐标
y.sort() # 从小到大排序
plt.show() # 展示箱线图
输出:
import matplotlib.pyplot as plt # 导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure() # 建立图像
p = data.boxplot(return_type='dict') # 画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() # 从小到大排序,该方法直接改变原对象
'''
用annotate添加注释
其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制
以下参数都是经过调试的,需要具体问题具体调试。
'''
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() # 展示箱线图
输出:

从上图中可以看出,箱型图中超过上下界的$8$个月销售额数据可能为异常值。结合具体业务可以把$865.0、4060.3、4065.2$归为正常值,把$22.0、51.0、60.0、6607.4、9106.44$归为异常值。最后确定过滤规则为日销售额在$400$元以下或$5000$元以上则属于异常数据,编写过滤程序,进行后续处理。
数据不一致性是指数据的矛盾性、不相容性。直接对不一致的数据进行挖掘,可能会产生与实际相违背的数据挖掘结果。
在数据挖掘过程中,不一致数据的产生主要发生在数据集成的过程中,可能是由于被挖掘数据来自于不同的数据源、对重复存放的数据未能进行一致性更新造成的。例如,两张表都存储了用户的电话号码,但在用户的电话号码发生改变时只更新了一张表中的数据,那么这两张表中就有了不一致数据。
对数据进行质量分析后,接下来可通过绘制图标、计算某些特征量等手段进行数据的特征分析。
分布分析能揭示数据的分布特征和分布类型。
对于定量变量而言,选择“组数”和“组宽”是做频率分布分析时最主要的问题,一般按照以下步骤进行:
第一步:求极差。
第二步:决定组距和组数。
第三步:决定分点(分布区间)。
第四步:列出频率分布表。
第五步:绘制频率分布直方图。
遵循的主要原则如下:
通过实例来运用分布分析对定量数据进行特征分析。
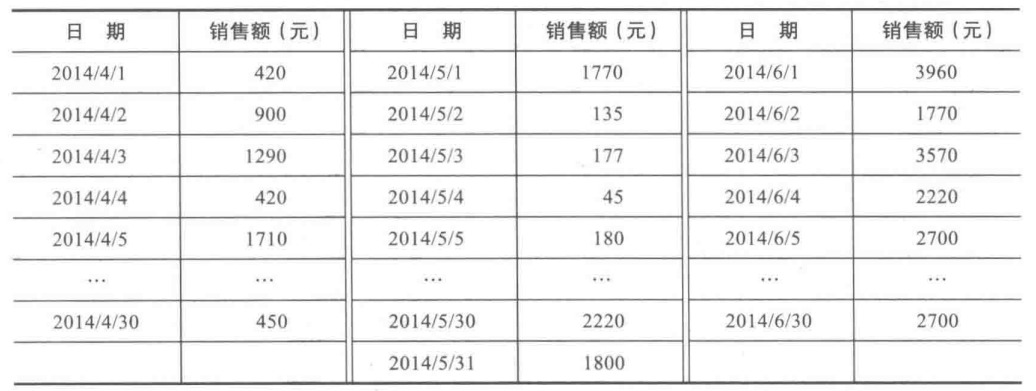
下表是菜品”捞起生鱼片“在2014年第二个季度的销售数据,绘制销售量的频率分布表、频率分布图,对该定量数据做出相应的分析。
(1)求极差
$$
\text{极差=最大值-最小值=3960-45=3915}
$$
(2)分组
这里根据业务数据的含义,可取组距为$500$,则组数公式如(2)所示。
$$
\text{组数=}\frac{\text{极差}}{\text{组距}}=\frac{3915}{500}=7.83\approx8
$$
(3)决定分点(分布区间)
分布区间如下表所示。

(4)绘制频率分布直方表
根据分组区间得到如下图所示的频率分布表。
第1列将数据所在的范围分成若干段,其中第1组段要包括最小值,最后一组段要包括最大值。习惯上将各组设为左开右闭的半开区间,如第一组段为$[0,500)$。
第2列组中值是各组段的代表值,由本组段的上限值和下限值相加除以2得到。
第3列和第4列分别为频数和频率。第5列是累计频率,根据实际情况看是否需要计算该列数据。

(5)绘制频率分布直方图
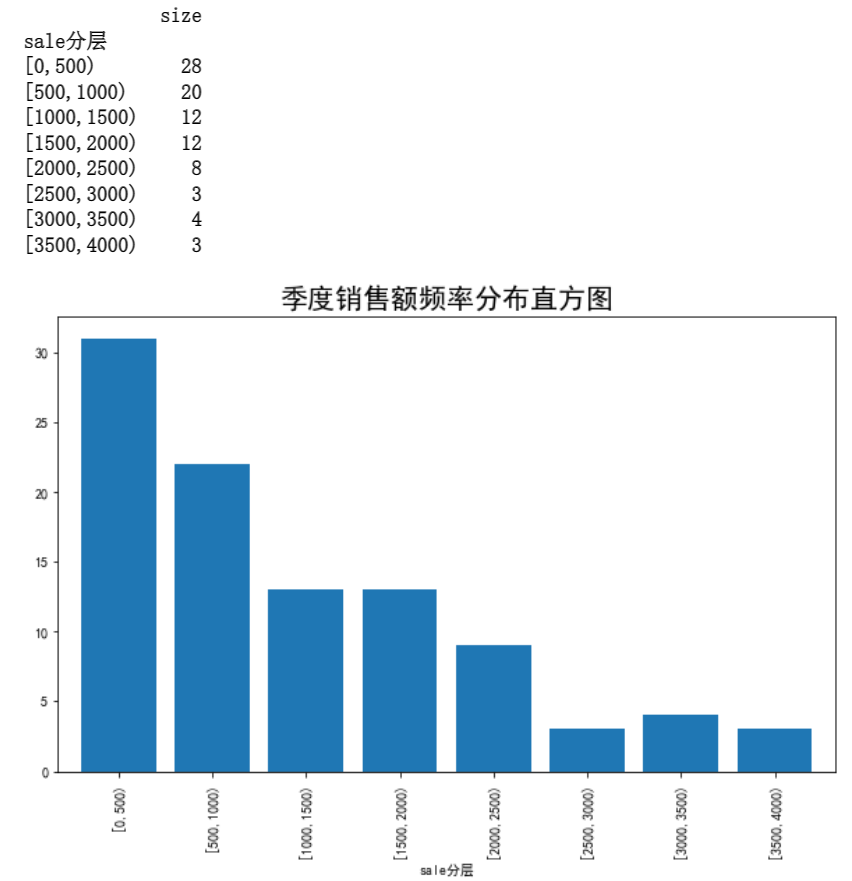
若以2014年第二季度“捞起生鱼片”这道菜每天的销售额组段为横轴,以各组段的频率密度(频率与组距之比)为纵轴,上表中的数据可绘制成频率分布直方图,如下所示。
方法一:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
catering_sale = '../data/catering_fish_congee.xls' # 餐饮数据
# 从 Excel 文件中读取数据,并将其存储为一个 pandas DataFrame
# 参数 catering_sale 是 Excel 文件名或文件路径
# 参数 names=['date', 'sale'] 指定了 DataFrame 的两列分别命名为 "date" 和 "sale"
# 此时DataFrame的索引为默认的数字索引,输出的格式如下:
'''
date sale
0 2022-01-01 100
1 2022-01-02 200
2 2022-01-03 150
'''
data = pd.read_excel(catering_sale,names = ['date','sale'])
# 将销售额按照指定的分层规则进行分层,并统计各分层的数量
bins = [0,500,1000,1500,2000,2500,3000,3500,4000]
labels = ['[0,500)','[500,1000)','[1000,1500)','[1500,2000)',
'[2000,2500)','[2500,3000)','[3000,3500)','[3500,4000)']
'''
使用 Pandas 的 pd.cut() 方法将销售额分层。
pd.cut() 方法需要传入三个参数:待分层的数据、分层的规则和分层的标签。
这里将销售额作为待分层的数据,将 bins 和 labels 分别作为分层的规则和标签。
具体来说,这段代码将销售额分成 8 个分层,分别是 [0,500)、[500,1000)
'''
data['sale分层'] = pd.cut(data.sale,bins,labels = labels)
'''
使用 data.groupby() 方法按照分层的结果进行分组,
并使用 ['sale'].agg([np.size]) 对分组结果进行统计。
这里将分组结果按照 sale分层 列进行分组,统计各分层中销售额的数量。
结果将保存在 aggResult 变量中。
需要注意的是,这里使用了 agg() 方法,但是在括号中传入的参数不是一个字典,
而是一个列表 [np.size]。
这是因为在 Pandas 0.25.0 版本以后,agg() 方法不再支持传入字典参数,
而是需要将要使用的聚合函数以列表的形式传入。
'''
aggResult = data.groupby(by = ['sale分层'])['sale'].agg([np.size])
print(aggResult)
# 计算各分层占比,并四舍五入保留两位小数
pAggResult = round(aggResult/aggResult.sum(),2) * 100
'''
pAggResult['size']:从上面代码中可以看到,
agg 函数的返回值是一个 DataFrame,其中包含了每个分组的销售额的个数,
因此这里使用 ['size'] 来获取销售额个数这一列。
.plot(kind='bar',width=0.8,fontsize=10):将销售额个数的数据进行可视化,
使用 kind='bar' 表示画出直方图,
width=0.8 表示每个直方图的宽度为 0.8, fontsize=10 表示字体的大小为 10。
'''
plt.figure(figsize = (10,6))
pAggResult['size'].plot(kind = 'bar',width = 0.8,fontsize = 10) # 绘率直方图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('季度销售额频率分布直方图',fontsize = 20)
plt.show()
输出:
方法二:
import pandas as pd
import numpy as np
catering_sale = '../data/catering_fish_congee.xls' # 餐饮数据
data = pd.read_excel(catering_sale,names=['date','sale']) # 读取数据,指定“日期”列为索引
import matplotlib.pyplot as plt
d = 500 # 设置组距
num_bins = round((max(data['sale']) - min(data['sale'])) / d) # 计算组数
plt.figure(figsize=(10,6)) # 设置图框大小尺寸
plt.hist(data['sale'], num_bins)
plt.xticks(range(0, 4000, d))
plt.xlabel('sale分层')
plt.grid()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('季度销售额频率分布直方图',fontsize=20)
plt.show()
输出:

对于定性变量,常常根据变量的分类类型来分组,可以采用饼图和条形图来描述定性变量的分布,代码如下所示:
import pandas as pd
import matplotlib.pyplot as plt
catering_dish_ptofit = '../data/catering_dish_profit.xls' # 餐饮数据
data = pd.read_excel(catering_dish_profit) # 读取数据,指定“日期列为索引”
# 绘制饼图
x = data['盈利']
labels = data['菜品名']
plt.fitgure(figsize = (8,6)) # 设置画布大小
plt.pie(x,labels = labels) # 绘制饼图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('菜品销售量分布(饼图)') # 设置标题
plt.axis('equal')
plt.show()
输出:
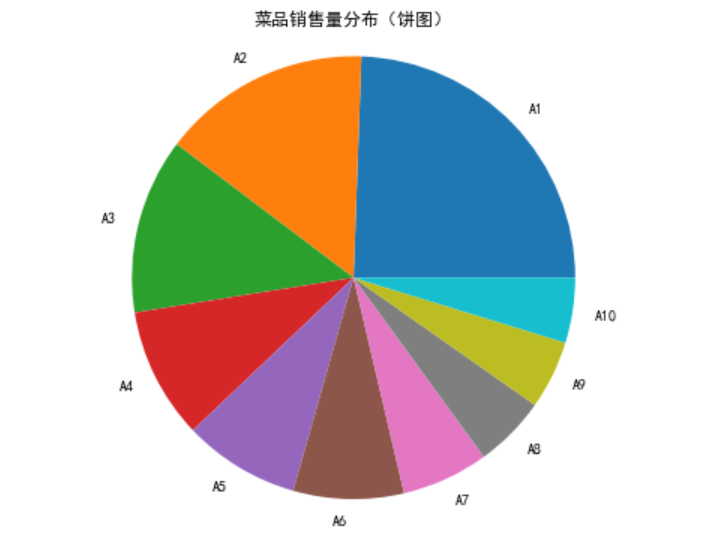
饼图的每一个扇形部分代表每一个类型的所占百分比或频数,根据定性变量的类型数目将饼图分为几个部分,每一部分的大小与每一类型的频数成正比,条形图的高度代表每一类型的百分比或频数,条形图的宽度没有意义。


